
For a large organization creating a coherent data ecosystem can be a major effort that requires assimilation of various existing processes, tools, and production systems (some using Machine Learning). With this high level of complexity, how can organizations look to optimize their Machine Learning workflow, and how can Machine Learning bring value sustainably?
Our team has been working with large and small-scale companies alike on this issue over many years. We penned this blog post to discuss the opportunities and considerations.
Why Automate the Workflow?
To generate value to business. By a large degree, implementing Machine Learning to create value is a natural extension of industrial automation. Computers exist to reduce time and effort required from humans. Adding Machine Learning capabilities to optimize valuable business decisions is an example of first-stage automation. That is, optimizing human involvement or the valuable output of a process by engaging a novel tool (Machine Learning in this case).
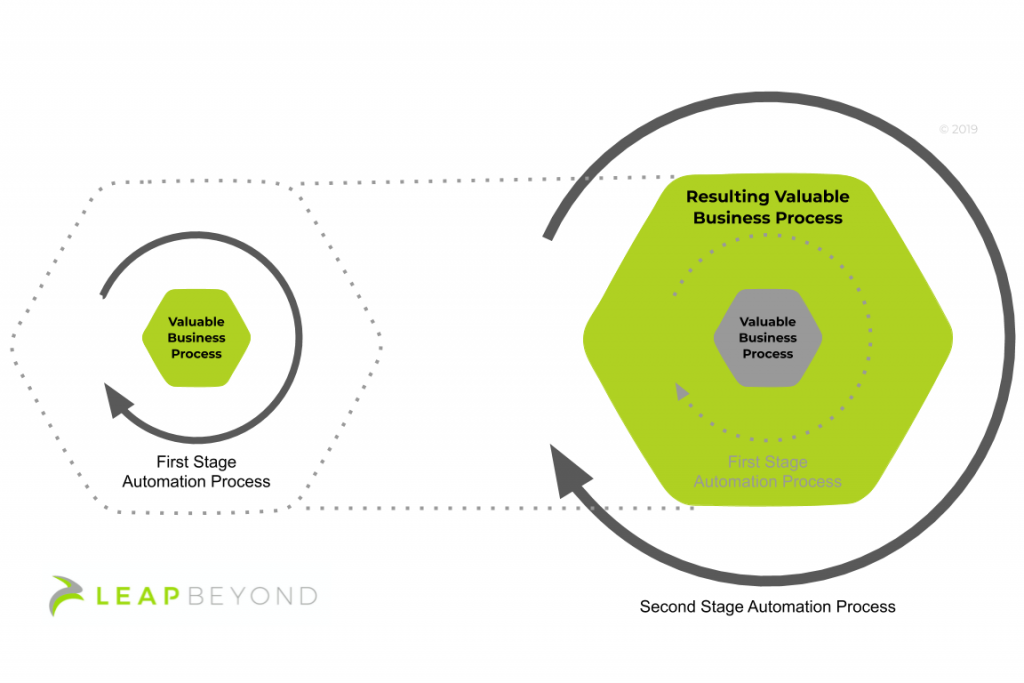
Automation amplifies value. If a process is valuable, it is also valuable to optimize/automate it. This is an example of value transfer. If a tool or process adds value to business, that tool or process gains a tangible value in itself. In this case, the Machine Learning process itself gains value if it is being used to optimize a valuable process.
Rinse and Repeat: Once a Machine Learning process has value, this too can be amplified by automating or optimizing it. This is a second-stage automation. Optimizing the usage of the tool now has additional business impact, and a tangible business value. For illustration, see the figure above.
To reduce human error and human training requirements. Ideally your new Data-Driven process crystallizes knowledge from many experts, with insights from Data which can be gradually improved over time. However, the more human involvement, the higher the risk of small mistakes building up over time or information being lost. This implies growing costs, more challenging governance and reduced robustness and auditability.
Automation gives rise to simplified, sustainable and auditable processes. When and where it’s valuable, sustainable Machine Learning then becomes an integral business-as-usual function.
How Can We Begin?
For sufficiently large organizations the myriad systems in production may initially look to be very far from a coherent ecosystem. Divergent processes, competing use cases, multiple data sources, data integration layers, and varied governance, may already be very diverse. Different business units often run competing programs or specific requirements-based implementations which either do not scale or do not transfer across units. What is then the route to build an optimized ecosystem?
At Leap Beyond, we consider this in terms of capability building blocks, for which each block itself is valuable as a tool across the organization, that can be built and adopted in synergy.
“Sustainable Machine Learning does not exist in a vacuum,
it exists embedded in a Data Ecosystem” – Leap Beyond
The diagram below collects building blocks towards a sustainable Machine Learning ecosystem. Each component block has a tangible value in itself, optimizes a small part of the whole, and builds upon the rest for a coherent final ecosystem.
Armed with such a roadmap a business can build block-wise capabilities one-at-a-time, together with the use cases which benefit most from them. Stepping towards the ecosystem picture and gaining value in every step. When fully implemented as an ecosystem, sustainable data products become business-as-usual output from your teams.
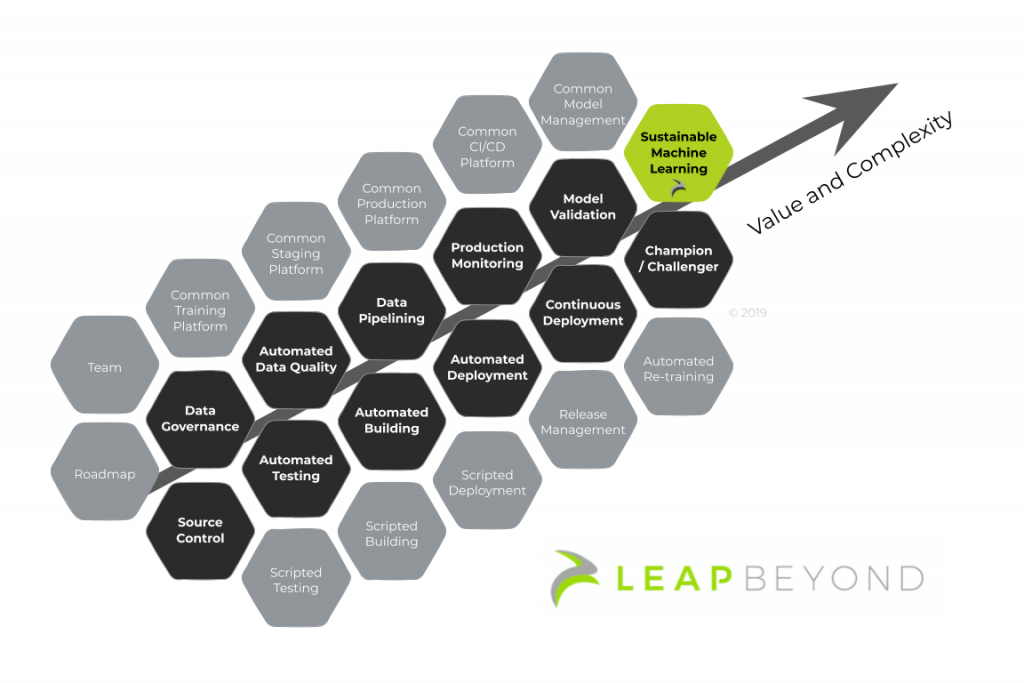 At Leap Beyond, we have collected insights from multiple industries and consolidated these with best practises that leverage both open source and proprietary offerings. Sustainable Machine Learning does not exist in a vacuum, it exists embedded in a data ecosystem. If you’re interested to hear more, or are looking to develop your data ecosystem in-house, we’re here to help.
At Leap Beyond, we have collected insights from multiple industries and consolidated these with best practises that leverage both open source and proprietary offerings. Sustainable Machine Learning does not exist in a vacuum, it exists embedded in a data ecosystem. If you’re interested to hear more, or are looking to develop your data ecosystem in-house, we’re here to help.